在當(dāng)今大數(shù)據(jù)技術(shù)生態(tài)中,HBase作為一款高性能、高可靠、面向列的分布式NoSQL數(shù)據(jù)庫(kù),已成為企業(yè)處理海量非結(jié)構(gòu)化或半結(jié)構(gòu)化數(shù)據(jù)的關(guān)鍵技術(shù)棧。無(wú)論是數(shù)據(jù)工程師、數(shù)據(jù)開發(fā)還是大數(shù)據(jù)架構(gòu)師的面試中,對(duì)HBase的深入理解往往是考察的重點(diǎn)。本文將從核心概念、數(shù)據(jù)處理與存儲(chǔ)支持服務(wù)等維度,系統(tǒng)解析HBase的技術(shù)精髓。
一、HBase的核心定位與架構(gòu)
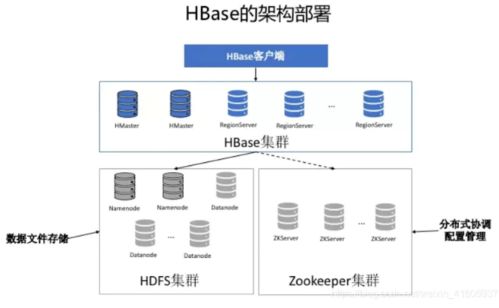
HBase構(gòu)建在Hadoop HDFS之上,專為處理大規(guī)模數(shù)據(jù)集而生。它本質(zhì)上是一個(gè)稀疏的、分布式、持久化的多維排序映射表,通過(guò)行鍵(Row Key)、列族(Column Family)、列限定符(Column Qualifier)和時(shí)間戳(Timestamp)四個(gè)維度來(lái)定位數(shù)據(jù)。其架構(gòu)主要包括以下幾個(gè)核心組件:
1. HMaster:負(fù)責(zé)RegionServer的負(fù)載均衡、Region的分配與遷移,以及DDL操作(如表創(chuàng)建、刪除)。
2. RegionServer:負(fù)責(zé)具體的數(shù)據(jù)讀寫請(qǐng)求,管理多個(gè)Region。
3. Region:HBase中數(shù)據(jù)分布和負(fù)載均衡的基本單位,一個(gè)表在水平方向上被劃分為一個(gè)或多個(gè)Region。
4. ZooKeeper:作為協(xié)調(diào)服務(wù),負(fù)責(zé)維護(hù)集群狀態(tài)、實(shí)現(xiàn)HMaster的高可用以及存儲(chǔ)元數(shù)據(jù)位置。
這種架構(gòu)確保了HBase具備線性擴(kuò)展能力,能夠通過(guò)簡(jiǎn)單增加機(jī)器來(lái)應(yīng)對(duì)數(shù)據(jù)量和訪問(wèn)量的增長(zhǎng)。
二、HBase的數(shù)據(jù)處理能力
HBase的數(shù)據(jù)處理能力是其核心價(jià)值之一,主要體現(xiàn)在高效的讀寫操作上。
- 寫入優(yōu)化:HBase采用LSM-Tree(日志結(jié)構(gòu)合并樹)作為其底層存儲(chǔ)模型。數(shù)據(jù)首先寫入內(nèi)存中的MemStore,當(dāng)達(dá)到一定閾值后,異步刷寫到磁盤形成不可變的HFile。這種順序?qū)懭敕绞綐O大地提升了寫入吞吐量,非常適合寫密集型的場(chǎng)景。
- 讀取優(yōu)化:讀取數(shù)據(jù)時(shí),系統(tǒng)會(huì)同時(shí)查詢MemStore和多個(gè)HFile,并通過(guò)布隆過(guò)濾器(Bloom Filter)和塊緩存(BlockCache)來(lái)加速查詢。布隆過(guò)濾器可以快速判斷某個(gè)數(shù)據(jù)塊中是否包含目標(biāo)行鍵,避免了不必要的磁盤I/O。
- 強(qiáng)一致性模型:在單個(gè)行鍵的維度上,HBase提供強(qiáng)一致性讀寫,所有客戶端看到的同一行數(shù)據(jù)順序是一致的。
- 豐富的API:除了傳統(tǒng)的Put、Get、Scan、Delete操作,HBase還支持通過(guò)協(xié)處理器(Coprocessor)實(shí)現(xiàn)服務(wù)端計(jì)算,如自定義過(guò)濾器、聚合操作等,將計(jì)算邏輯推送到數(shù)據(jù)所在服務(wù)器,減少網(wǎng)絡(luò)傳輸開銷。
三、HBase的存儲(chǔ)支持服務(wù)
HBase的強(qiáng)大離不開其背后穩(wěn)固的存儲(chǔ)支持服務(wù),這確保了數(shù)據(jù)的持久性、可靠性與可管理性。
- 基于HDFS的持久化存儲(chǔ):HFile最終存儲(chǔ)在HDFS上,天然繼承了HDFS的高可靠、高容錯(cuò)特性。數(shù)據(jù)默認(rèn)多副本存儲(chǔ),硬件故障不會(huì)導(dǎo)致數(shù)據(jù)丟失。
- Region的自動(dòng)分片與負(fù)載均衡:隨著數(shù)據(jù)增長(zhǎng),Region會(huì)自動(dòng)分裂。HMaster會(huì)監(jiān)控RegionServer的負(fù)載情況,將Region在集群內(nèi)重新分布,以實(shí)現(xiàn)負(fù)載均衡,保證集群性能穩(wěn)定。
- 數(shù)據(jù)壓縮與編碼:HBase支持對(duì)HFile進(jìn)行多種算法(如GZ、LZO、Snappy)的壓縮,以及對(duì)數(shù)據(jù)進(jìn)行前綴編碼、差分編碼等,有效節(jié)約存儲(chǔ)空間,提升I/O效率。
- 完善的運(yùn)維與監(jiān)控:HBase提供了豐富的Shell命令、Web UI以及與JMX的集成,方便管理員進(jìn)行集群管理、狀態(tài)監(jiān)控和性能調(diào)優(yōu)。其與Hadoop生態(tài)的深度集成,也使得數(shù)據(jù)導(dǎo)入導(dǎo)出(如通過(guò)Spark、Flink、Sqoop)非常便捷。
四、典型應(yīng)用場(chǎng)景與面試要點(diǎn)
HBase非常適合需要隨機(jī)、實(shí)時(shí)讀寫訪問(wèn)超大規(guī)模數(shù)據(jù)集的場(chǎng)景,例如:
- 用戶畫像與推薦系統(tǒng):存儲(chǔ)和快速查詢用戶行為、屬性標(biāo)簽。
- 時(shí)序數(shù)據(jù):存儲(chǔ)物聯(lián)網(wǎng)傳感器數(shù)據(jù)、監(jiān)控指標(biāo)。
- 消息通信:存儲(chǔ)在線消息、郵件數(shù)據(jù)。
- 作為大數(shù)據(jù)平臺(tái)的查詢結(jié)果集緩存。
在面試中,除了上述原理,候選人還需準(zhǔn)備:
- RowKey設(shè)計(jì)原則(散列、有序、長(zhǎng)度),這是影響性能的關(guān)鍵。
- HBase與RDBMS、Hive、Cassandra等的對(duì)比。
- 讀寫流程的詳細(xì)步驟(如一次Put操作如何最終落盤)。
- Compaction(合并)機(jī)制的作用與類型(Minor/Major)。
- 如何排查和解決熱點(diǎn)Region問(wèn)題。
HBase以其卓越的擴(kuò)展性、靈活的數(shù)據(jù)模型和強(qiáng)大的實(shí)時(shí)讀寫能力,在大數(shù)據(jù)存儲(chǔ)領(lǐng)域占據(jù)著不可替代的地位。深入理解其數(shù)據(jù)處理邏輯和存儲(chǔ)支持服務(wù),不僅能幫助開發(fā)者和架構(gòu)師更好地駕馭這項(xiàng)技術(shù),也是在大數(shù)據(jù)面試中脫穎而出的重要籌碼。